Product Overview
The OEM-SWSB voice print recognition module collects a large amount of sound data and trains these data with deep learning algorithms to extract useful features and conduct model optimization. Then, the input sounds are compared with the known sound model, and the different sound source types are automatically distinguished from the source by calculating the distance or similarity between the features of the input sounds and the model.
major function
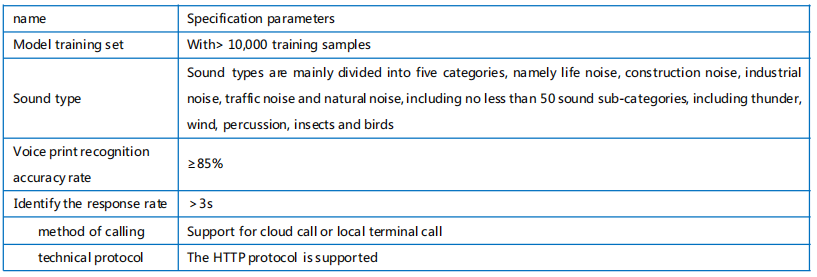
AI deep algorithm model, massive voice pattern sample training database, based on Pytorch open source architecture, fast identification response rate, identification accuracy of 85%, automatic association of sound source events, modular fast disassembly and deployment, support for personalized voice print database construction, local database and cloud database flexible selection;
Technical parameter table
Soundprint library classification
Level 1 classification: five categories, natural noise, living noise, construction noise, industrial noise, traffic noise;
Classification basis: HJ 640 standard, noise pollution prevention and control report, noise environmental assessment, noise method, etc.;
Secondary classification: according to the common characteristics of application scenarios or sound;
Three-level classification: as the identification results of sub-stations, the original sound types are merged and optimized in the same category.
Constant temperature heating, so that the instrument can also operate stably in high and low temperature weather;
Cut off the network to remove the network instability, to ensure the data upload rate;
Excessive alarm alarm, graded alarm timely inter vention and control of excessive noise pollution;
Remote send ACT command to open the electrostatic motivator for automatic calibration to reduce unnecessary on-site manual operation;

